
過去の引継ぎフォルダや古いバックアップを開くと、「これ、何で作った文書だ?」というファイルが必ず混ざります。拡張子が見慣れなかったり、開けても文字化けしたりして作業が滞る原因にもなります。
ここでは、古いビジネス文書を「ワープロ系」と「表計算系」に区分し、壊さずに中身を取り出し、現行アプリで扱える形にする基本的な流れを取り上げてみました。
ワープロ文書の典型パターン:一太郎・Word・書院・オアシスなど
ビジネス文書は、拡張子で当たりを付けるのが基本です。代表的なのは「.doc」「.docx」「.rtf」「.txt」です。古い環境では、メーカー/機種依存の拡張子が付くことがあり、見慣れない拡張子でも“文書らしい名前(議事録・報告・案内・契約など)”が並ぶフォルダはワープロ系のファイルが混在している可能性が高いです。
また、ファイル名が不自然に短い場合は、MS-DOS時代にあったファイル名の文字数制限の影響などが疑われます。
半角最大8文字+拡張子3文字という枠は日本語環境に当てはめると、全角1文字は半角2文字相当として扱われやすいため、結果として「全角4文字程度」の短い名前になりがちでした。
短いファイル名が固まっているフォルダは、当時のワープロ系ソフトで作成された文書が混じっている可能性が高いという判断材料になります。
表計算の典型パターン:Excel・Lotus1-2-3・三四郎など
表計算もワープロ文書と同様に、まず拡張子を判断基準の目安にします。Excelは「.xls」「.xlsx」「.csv」が中心。加えて、古い業務環境だとLotusの表計算(例:.wk1/.wk3/.123)や、JustSystemsの表計算(例:三四郎系の拡張子)などが混在することがあります。
見慣れない拡張子の場合でも、ファイル名に「台帳・一覧・集計・在庫・売上・原価」などが多いフォルダは表計算ソフトで編集されたファイルとして扱うのが合理的です。
表計算ファイルは世代の違うアプリケーションで開くと関数と呼ばれる数式や書式が崩れることがあります。
この一見文字化けにも見える表示の崩れをいかに最小限に抑えられるかが、お宝データを復活させる際の重要な課題にもなります。
対応する現行アプリケーションへの変換方法
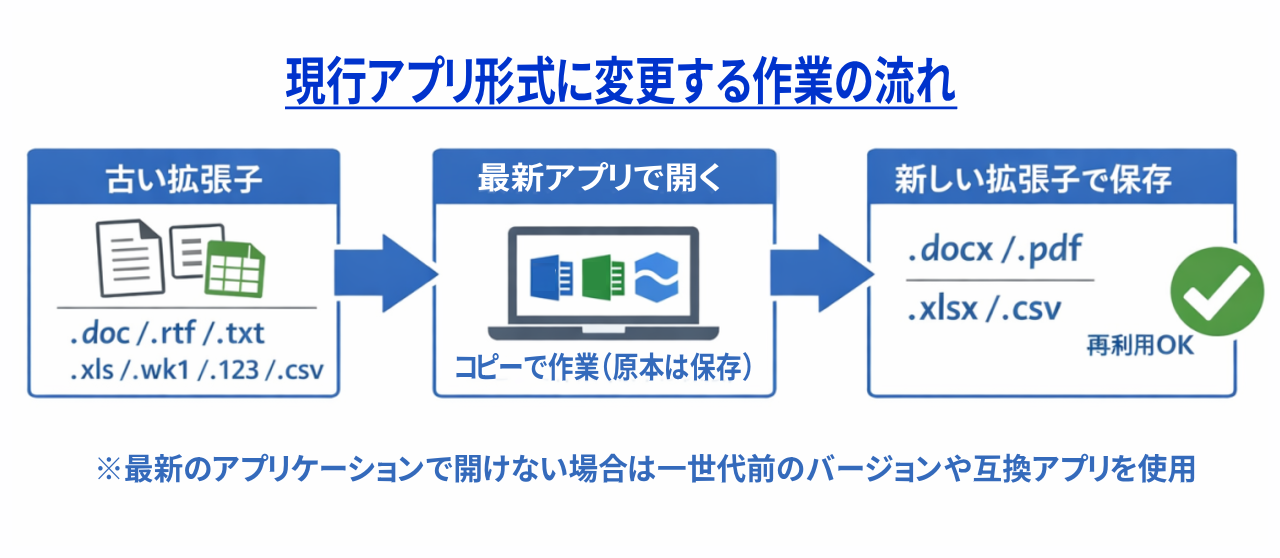
古い形式のファイルを現行アプリケーションで扱うには変換の手順に入る前に原本を回避する手順を怠らないことが重要になります。
「原本をコピー→コピーを開く(閲覧優先)→別形式で書き出す」です。ワープロ系は出来れば現在主流のWord形式に近づけるのが一つの目標になります。難しければ最低限文字情報を判別しやすいようPDFや.txt形式などで保管できないかを検討することになります。
表計算系も一般的なExcel形式(XLSX)での保存を目指します。難しければCSVへの変換で妥協するなどがありますが、アプリケーションの違いにより起きる関数の変換作業は手動でやらなければならないことも多く、どこまで現行アプリに対応させるかも課題の一つと言えるでしょう。
レアなビジネスファイル
